In recent years, instruction-tuned Large Multimodal Models (LMMs) have been successful at several tasks, including image captioning and visual question answering; yet leveraging these models remains an open question for robotics. Prior LMMs for robotics applications have been extensively trained on language and action data, but their ability to generalize in different settings has often been less than desired. To address this, we introduce LLARVA, a model trained with a novel instruction tuning method that leverages structured prompts to unify a range of robotic learning tasks, scenarios, and environments. Additionally, we show that predicting intermediate 2-D representations, which we refer to as "visual traces", can help further align vision and action spaces for robot learning. We generate 8.5M image-visual trace pairs from the Open X-Embodiment dataset in order to pre-train our model, and we evaluate on 18 different tasks in the RLBench simulator as well as a physical Franka Emika Panda 7-DoF robot. Our experiments yield strong performance, demonstrating that LLARVA — using 2-D and language representations — performs well compared to several contemporary baselines, and can generalize across various robot environments and configurations.

We introduce a novel instruction tuning method that leverages structured prompts to unify a range of robotic learning tasks, scenarios, and environments. In particular, the model works via a language instruction that contains robot model, control mode, robot task, proprioceptive information, and number of predicted steps , and outputs text with the next robot action(s) and the visual trace for the remainder of the episode. The concept of the 2-D visual trace is introduced to help localize the end-effector and further align the vision and action spaces.
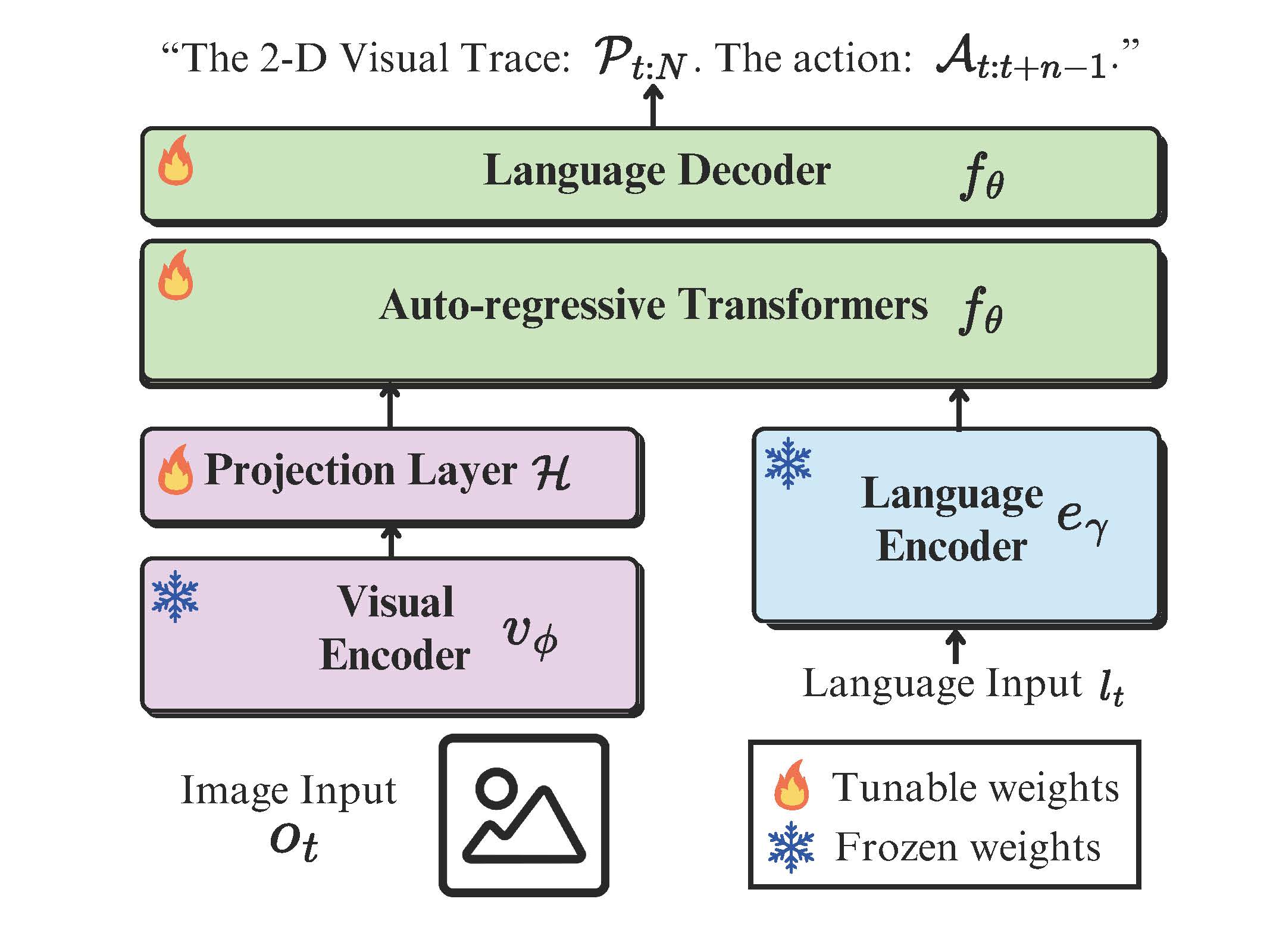
In our proposed pipeline, the input image undergoes processing by the frozen vision encoder \( v_{\phi}(\cdot) \), which extracts visual features and projects into a latent space via an MLP layer \( \mathcal{H} \). This aligns the visual features with the dimensionality of the language tokens. Simultaneously, the language input undergoes tokenization using a language encoder. The visual tokens and word tokens are then concatenated and fed into the auto-regressive transformers of the LMM \( f_{\theta} \), which are trained for next-token prediction.
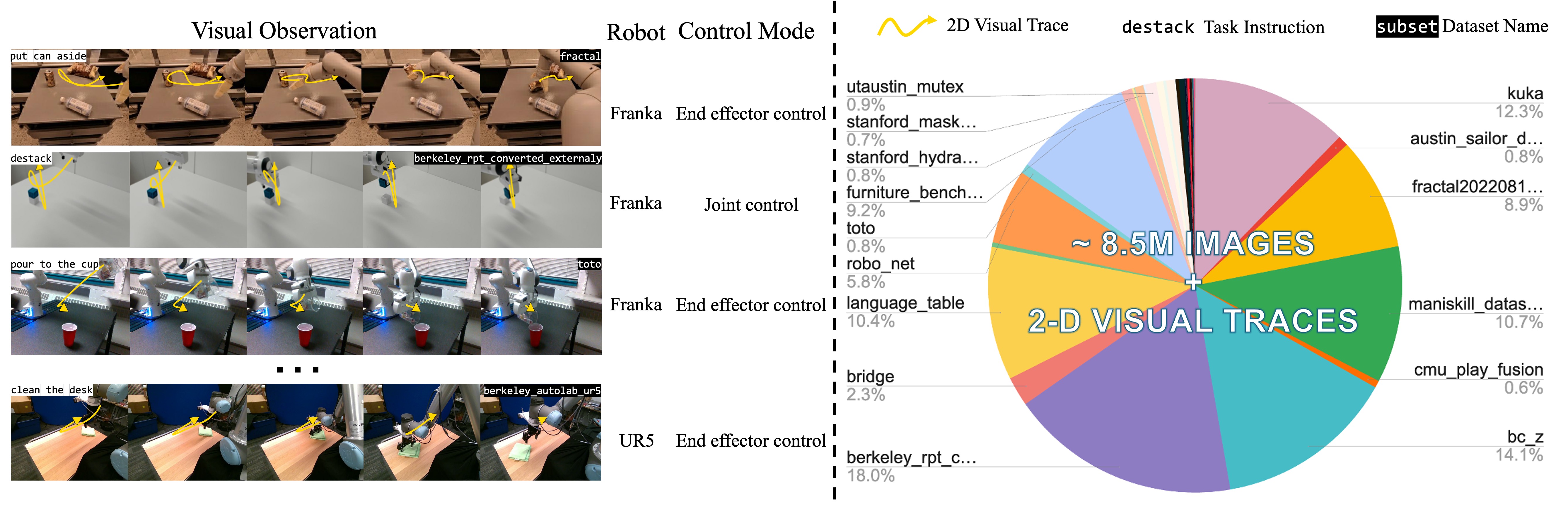
For the pre-training of LLARVA, we generate 8.5M image-visual trace pairs from the Open X-Embodiment (OXE) dataset. Our dataset consists of images from a diverse collection of 37 OXE subsets with 13 different robots, including a wide assortment of tasks, environments, cameras (and thus images), and end-effectors, among other factors. For each image in an episode, we calculate the 2-D visual trace of the end-effector \( \mathcal{P}_{t:N} \). For this purpose, we use a bounding box detector that is trained specifically on each of the different end-effectors in OXE.
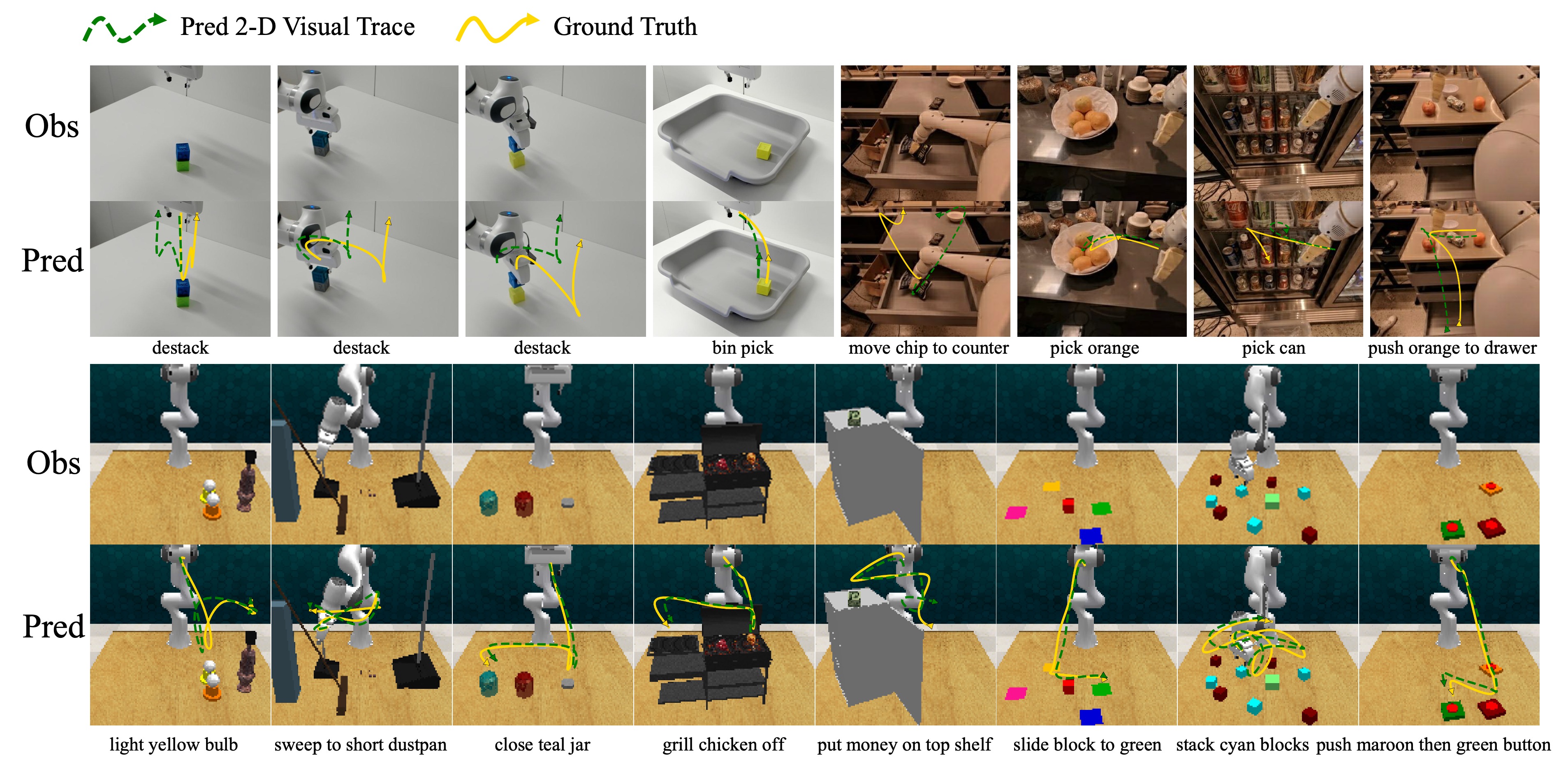
We show visual traces that our model can plan alternative yet correct paths. For example, in the top left image, the gripper takes a different path (go left) than the ground truth (go right), yet it still succeeds in destacking the cube. The above figure also shows qualitatively that the visual trace can help with long-horizon tasks by acting as a memory buffer that compensates for the limited number of previous robotic states the model can handle. For instance, in the bottom right, the task is "push maroon button, then push green button". It can be seen that the visual trace helps the model reach the "green button" after finishing the first subtask.
@misc{niu2024llarva,
title={LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning},
author={Dantong Niu and Yuvan Sharma and Giscard Biamby and Jerome Quenum and Yutong Bai and Baifeng Shi and Trevor Darrell and Roei Herzig},
year={2024}
}